Deploy Diffusion Models on Lambdas

Introduction
Diffusion models have taken the world by storm! The shear delight inherent in a prediction is rarely found in other models in this space. I’ve never felt as happy with predicting the number of likes a video will recieve as I do when I get a beautiful rendition of a cat in a top hat. With the explosion of these models comes the need for managing and working with their deployments. There are a lot of really good ways to deploy these models. I wanted to have a little bit of fun and see if we could deploy a diffusion model to a Lambda function. Why would we want to do this you might ask? The short answer is, it’s fun. The real answer is Lambdas are great for creating proof of concept work and trying out ideas. As a data scientist getting your models into peoples hands is almost more important than the models you build. Lambdas are also free when they aren’t running. So you might have a really low load application where you want stable diffusion support to test the waters before going HAM and splurging for GPUs. In this tutorial we’ll talk about using Docker to package your models on lambda. We’re doing this for a diffusion model but the ideas can be applied to a wide variety of model types.
This tutorial will walk through in order:
-
Using AWS CDK to create an IAM secured Lambda Function.
-
Securly call the Lambda function from our local machine.
-
Converting that Lambda to a Docker based deployment.
-
Add diffusion model to the container.
-
The full code for this example can be found on my GitHub here
Appeal to Reader
If you pay for Medium, or haven’t used your free articles for this month, please consider reading this article there. I post all of my articles here for free so everyone can access them, but I also like beer and Medium is a good way to collect some beer money : ). So please consider buying me a beer by reading this article on Medium.
Architecture
The architecture for this project is devilishly simple. We simply create a Lambda function that is powered by a container in ECR. It’s one of the nice things about building prototype systems in Lambda.
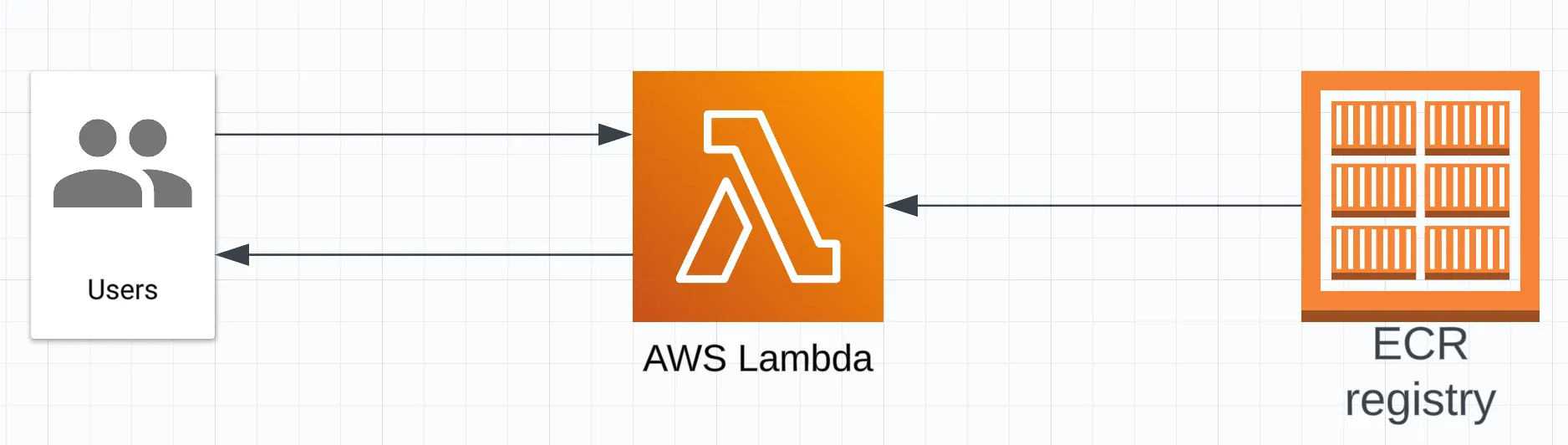
AWS Lambda has a number of incredibly nice things about it including:
-
They are free when they aren’t running, and inexpensive when run infrequently.
-
They are very quick to deploy and iterate on.
-
They are simple to reason about.
There are some drawbacks though:
-
Lambdas have very limited memory only 10GB of RAM, 250MB deployment package size, and 10GB max container size.
-
Lambdas have cold start time, if they haven’t been called recently they take time to spin up and initialize.
-
No GPUs :(
Building a simple Lambda Function with a URL
We’ll begin by using AWS CDK to create a Lambda function that says “Hello World!”. Before starting make sure you’ve installed CDK. Create a project folder, and then initialize the project with an empty stack.
mkdir lambda-diffusion cd lambda-diffusion cdk init sample-app - language python Now that our project is initialized we can start building out our infrastructure inside of lambda_diffusion/lambda_diffusion_stack.py. The main character in our stack today is the Lambda function. Here we create a Lambda function that will just return the string “Hello World”. We do this inline for simplicity but will refactor out the Lambda to it’s own file later.
from constructs import Construct from aws_cdk import ( Stack, aws_lambda as _lambda, CfnOutput, aws_iam as iam, aws_secretsmanager as secretsmanager, ) import aws_cdk as cdk
class LambdaDiffusionStack(Stack):
```
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Define the Lambda function with a very simple Hello World response inline
self.diffusion_fn = _lambda.Function(
self,
"DiffusionFunction",
runtime=_lambda.Runtime.PYTHON_3_10,
handler="index.handler",
code=_lambda.Code.from_inline(
"def handler(event, context):\n"
" return {\n"
' "statusCode": 200,\n'
' "body": "Hello, World!"\n'
" }\n"
),
)
```This is great, but there is no easy and secure way to access it. We need to expose the lambda externally in order to use it. In CDK this is a simple one line where we add a function url to our Lambda. We also use CfnOutput to print out the URL. This makes it easy to find without poking around in the the AWS console.
```
# Create a function URL that we can call to invoke the lambda function.
self.diffusion_fn_url = self.diffusion_fn.add_function_url(
auth_type=_lambda.FunctionUrlAuthType.NONE
)
# Add the url to the cloud formation output so it's easy to find
CfnOutput(self, "LambdaUrl", value=self.diffusion_fn_url.url)
``````
cdk bootstrap
cdk deploy
```After the deployment you should see something like this:

That URL is what we passed to CfnOutput and contains the URL of our Lambda. If you put that in your browser you should see:
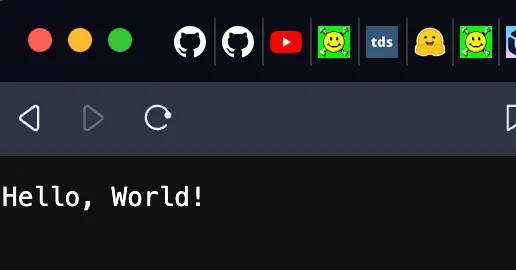
Nice! We now have a Lambda function that we can make get requests to which returns “Hello World”. There is one huge problem though. It’s not secure. Anyone on the public internet can access our endpoint. That could become very expensive 🤑.
Secure our Lambda URL
To secure our endpoint we’re going to use IAM and AWS’ SigV4 auth to authenticate with it. We’re not going to talk about the particulars of how SigV4 works because the boto libraries have some nice abstractions which make this easy. Let’s secure our endpoint with IAM update the URL with the AWS_IAM auth type.
```
self.diffusion_fn_url = self.diffusion_fn.add_function_url( auth_type=_lambda.FunctionUrlAuthType.AWS_IAM )
```If you redeploy and head to the URL you should see:
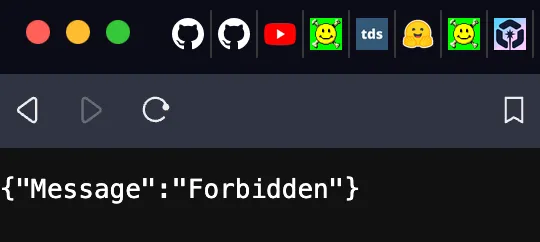
Our endpoint is now secure! It’s so secure in fact not even we can access it 😅. The IAM based authentication uses a user based IAM credentials to do the authentication hand shake with AWS. We need to create an IAM user, give them sufficient permissions to access our endpoint and then save the credentials. Using CDK’s iam package we can create a user and then a policy which grants that user the ability to invoke our specific Lambda Function URL. You can see this in the action and the specific resource. Once created this policy needs to be attached to the user.
```
# Create an IAM user with permissions to invoke the Lambda function
iam_user = iam.User(self, "LambdaInvokerUser")
policy = iam.Policy(
self,
"LambdaInvokePolicy",
statements=[
iam.PolicyStatement(
actions=["lambda:InvokeFunctionUrl"],
resources=[self.diffusion_fn.function_arn],
)
],
)
iam_user.attach_inline_policy(policy)
```Great! We now have a user who can technically access this endpoint. That doesn’t do us much good when it comes to programatic access. The next step is to create acceess keys for this user and save them as a secret so that we can access them later. Here we create an access key for the user we just created and then we store that key in AWS’ secrets manager. With this key saved we have everything we need to authenticate and access our endpoint.
```
# Create access keys for the IAM user
access_key = iam.AccessKey(
self, "DiffusionLambdaInvokerUserAccessKey", user=iam_user
)
# Store the access keys in Secrets Manager
secret = secretsmanager.Secret(
self,
id="DiffusionLambdaInvokerUserCredentials",
secret_object_value={
"AWS_ACCESS_KEY_ID": cdk.SecretValue.unsafe_plain_text(
access_key.access_key_id
),
"AWS_SECRET_ACCESS_KEY": access_key.secret_access_key,
},
)
```Head over to secrets manager in the cloud console and save the credentials. You can then create a boto3 session with these which will be used to authenticate requests.
```
from botocore.auth import SigV4Auth
from botocore.awsrequest import AWSRequest
import botocore
import boto3
import json
from typing import Any, Dict, Optional, Union
import requests
# Store the credentials for the user we created above.
credentials = {
"AWS_ACCESS_KEY_ID": "...",
"AWS_SECRET_ACCESS_KEY": "...",
}
# Create an active session based on the credentials
session = boto3.Session(
aws_access_key_id=credentials["AWS_ACCESS_KEY_ID"],
aws_secret_access_key=credentials["AWS_SECRET_ACCESS_KEY"],
region_name="us-west-2",
)
credentials = session.get_credentials().get_frozen_credentials()
```So far so good. The next bit is kind of a long function but at it’s core it’s very simple. We take the frozen session credentials from above and use them with the SigV4Auth method provided by AWS to sign the request. This method handles using the credentials to do the authentication for us and update the headers. With the correct headers in place we can use the traditional requests library to make the request.
```
def signed_request(
credentials: botocore.credentials.ReadOnlyCredentials,
method: str,
url: str,
service_name: str,
region: str,
data: Optional[Union[str, Dict[str, Any]]] = None,
params: Optional[Dict[str, str]] = None,
headers: Optional[Dict[str, str]] = None,
) -> requests.Response:
"""
Sign a request using SigV4 and return its response.
:param credentials: The boto3 session credentials.
:param method: HTTP method (GET, POST, etc.).
:param url: The endpoint URL.
:param service_name: The AWS service name (e.g., execute-api for API Gateway, lambda for Lambda).
:param region: AWS region (e.g., us-east-1).
:param data: Request payload (optional).
:param params: Query parameters (optional).
:param headers: HTTP headers (optional).
"""
headers = headers or {}
if isinstance(data, dict):
headers["Content-Type"] = "application/json"
data = json.dumps(data)
headers["Content-Length"] = str(len(data.encode("utf-8")))
request = AWSRequest(
method=method, url=url, data=data, params=params, headers=headers
)
SigV4Auth(credentials, service_name, region).add_auth(request)
return requests.request(
method=method, url=url, headers=dict(request.headers), data=data
)
response = signed_request(
credentials,
"GET",
"https://ybajg5r7frv6zmbjeot3yiaiee0askzy.lambda-url.us-west-2.on.aws/",
service_name="lambda",
region="us-west-2",
)
print(response.text)
```If you give this a whirl you should get back the text “Hello World”. Our endpoint is now secure and we can call it programmatically! This technique is really useful in AWS and is a great way to auth with a lot of services. With these tools under your belt you can make all kinds of super quick secure APIs to test ideas. We’re interested in putting a non trivial model up so next we’ll tackle some changes to our Lambda that must be made to acomodate big packages.
Dockerizing our Lambda
Remember in the beginning when we were talking about some of the Lambda downsides? Well this is where one of them rears it’s ugly head. The deployment package size for basic Lambdas is limited to 250MB. That might seem like a lot when it comes to code but in order to use a diffusion model here we’ll need the torch , diffusers , and transformers libraries. torch alone is about 800MB so that just won’t work with the basic Lambda.
We have a few options. Wecan try and pair down the library to only the components that weneed, however that can be a ton of work and hard to maintain as libraries change. So I don’t usually like to do this.
We can look at alternative packages for deployment. For example, using ONNX let’s us install the much smaller onnxruntime library and run models on basic Lambdas. Initially I tried this route because optimizing and quantizing models has some real advantages! However, when doing inference using ORTStableDiffusionXLPipeline I noticed that the system was gobbling up over 20GBs of RAM! Since Lambda’s only support a maximum of 10GB this isn’t going to work either. If you’re interested in exploring deploying some ONNX models checkout my other blog post on deploying an ONNX model to Sagemaker.
The method I usually go with if I need big packages is to user a Docker based Lambda. In this paradigm we build our Lambda function on a container and then AWS loads the container into the Lambda service. It can do this because we setup a standard entrypoint and base image for the Lambda. Let’s create our container. It’s pretty simple. We use the Lambda Python 3.10 base image, we install our libraries, we copy our main function over and set the entrypoing to main.handler . No sweat.
```
# Use the official AWS Lambda Python base image
FROM public.ecr.aws/lambda/python:3.10
# Install any dependencies
RUN pip install --no-cache-dir diffusers torch transformers
# Copy the function code
COPY main.py ${LAMBDA_TASK_ROOT}
# Command to run the Lambda function
CMD ["main.handler"]
```To update the CDK to work with this container we’ll need to update our package structure a bit. Create a folder in lambda_diffusion called lambda and inside of it add the Dockerfile and a main.py file. This main.py will contain the python code to run our function.
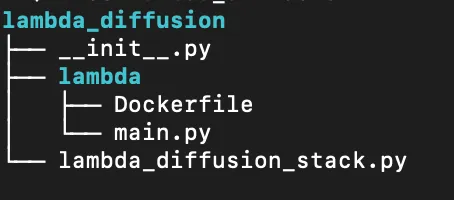
Update the CDK to use Docker and the new directory structure. Simply replace your old diffusion_fn with this new one. We change the Lambda type to be DockerImageFunction. We also need to update where CDK should look to build the image. We do that with the from_image_asset command and point it tou our lambda folder. This tells CDK to build the container with the context of everything in that folder. One more little gotcha which can crop up is making sure that the build platform is consistent between your build environment and your deployment environment. We specify that we want to build this on LINUX_AMD64 if you’re using an ARM chip without this command your image won’t run in the cloud.
```
# Define the Lambda function with a very simple Hello World response inline
self.diffusion_fn = _lambda.DockerImageFunction(
self,
"DiffusionFunction",
code=_lambda.DockerImageCode.from_image_asset(
os.path.join(os.path.dirname(__file__), "lambda"),
platform=ecr_assets.Platform.LINUX_AMD64,
),
timeout=cdk.Duration.seconds(600),
memory_size=10240,
)
```We also need to fill in our main.py function with what we had before.
```
def handler(event, context):
return {"statusCode": 200, "body": "Hello, World!"}
```This will get built into the container and run when we execute our Lambda. Deploy the service and hit it using the SigV4 auth to make sure everything is working. If we’ve done our part correctly we should still see the “Hello World” message as before. One thing to note is that now we have to build a container so things take a little bit longer to deploy than before. This is one of the downsides of container based Lambdas.
Adding a Diffusion Model
Finally, the part we’ve been building to, actually deploying a diffusion model on this thing. There was a lot of base work to get all of the pieces in place but now it should be pretty quick. We just need to update our main.py function to two things:
-
Load in the diffusion model.
-
Accept a prompt for our image.
-
Run the diffusion steps.
-
Encode our image as a string.
-
Send it back to the user.
In theory it’s not too complicated. It turns out in practice it’s pretty easy too : ). In the below code we parse out the parameters in our request that we sent over and load in the model.
```
import base64
import os
import json
from io import BytesIO
from diffusers import DiffusionPipeline
def handler(event, context):
# Load in the event dictionary as JSON and parse out the two parameters
event_dict = json.loads(event["body"])
prompt = event_dict["prompt"]
num_inference_steps = event_dict.get("num_inference_steps", 4)
# Initialize the model if it hasn't been loaded yet
model_path = ...
print(f"Initializing model at {model_path}")
pipe = DiffusionPipeline.from_pretrained(model_path)
```We are more or less using the segmind/tiny-sd model directly as is done in the docs but loading it in is going to require a little bit of work. We can’t just call it as the docs suggest and have the diffusers library download it because Lambda’s don’t have writeable disk. They have a writeable /tmp folder. If we wanted to, we could update the ephemeral storage on the Lambda to be 6GB and then import the model like:
```
# Initialize the model if it hasn't been loaded yet
model_path = "segmind/tiny"
print(f"Initializing model at {model_path}")
pipe = DiffusionPipeline.from_pretrained(model_path, cache_dir="/tmp")
```However this would require us to download the model every time the lambda starts up! That could be a lot of extra time and possibly a lot of extra cash. A much better approach is to bake the model directly into the container. To do that download the model locally. I like to use the above code to set the cache_dir where I want it. In this case we want to put it in the context of our docke rbuild so replace the cache_dir path above with:
{path_to_cdk_project}/lambda_diffusion/lambda
That’s it. It should download the model to that folder and your new folder structure should look something like this:
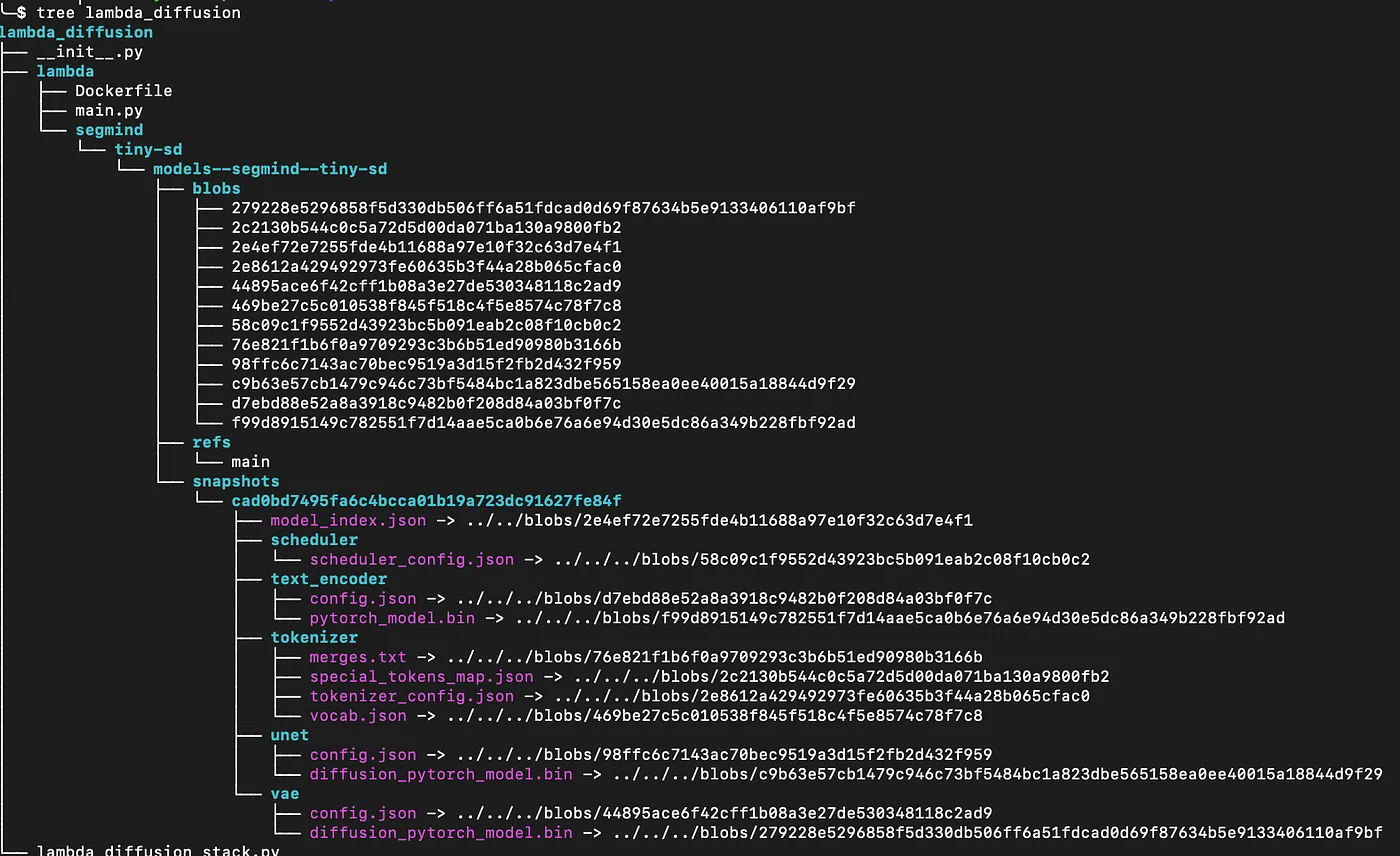
There is a lot of stuff in here now but it’s all related to the model. With the model in the context of the container we need to update the Dockerfile to copy the model in. Add the following line to the Dockerfile toward the top. You don’t want this to get rerun if you change your main.py function.
```
# Copy the model for the lambda
COPY segmind ${LAMBDA_TASK_ROOT}/segmind
```Now we can load in our model inside of main.py using it’s path in the Lambda container.
```
model_path = os.path.join(
os.environ["LAMBDA_TASK_ROOT"],
"segmind/tiny-sd/models--segmind--tiny-sd/snapshots/cad0bd7495fa6c4bcca01b19a723dc91627fe84f",
)
print(f"Initializing model at {model_path}")
pipe = DiffusionPipeline.from_pretrained(model_path)
```We can use this model to generate an image:
```
# Generate the image
print(f"Generating image for prompt: {prompt}")
image = pipe(
prompt=prompt,
num_inference_steps=num_inference_steps,
output_type="pil",
low_memory=True,
).images[0]
```Then in order to return the image to the user we need to base64 encode it as a string.
```
# Encode the image to base64
print("Encoding image")
buffered = BytesIO()
image.save(buffered, format="PNG")
img_str = base64.b64encode(buffered.getvalue()).decode("utf-8")
```The full file looks like:
```
import base64
import os
import json
from io import BytesIO
from diffusers import DiffusionPipeline
def handler(event, context):
global pipe
event_dict = json.loads(event["body"])
prompt = event_dict["prompt"]
num_inference_steps = event_dict.get("num_inference_steps", 4)
# Initialize the model if it hasn't been loaded yet
model_path = os.path.join(
os.environ["LAMBDA_TASK_ROOT"],
"segmind/tiny-sd/models--segmind--tiny-sd/snapshots/cad0bd7495fa6c4bcca01b19a723dc91627fe84f",
)
print(f"Initializing model at {model_path}")
pipe = DiffusionPipeline.from_pretrained(model_path)
# Generate the image
print(f"Generating image for prompt: {prompt}")
image = pipe(
prompt=prompt,
num_inference_steps=num_inference_steps,
output_type="pil",
low_memory=True,
).images[0]
# Encode the image to base64
print("Encoding image")
buffered = BytesIO()
image.save(buffered, format="PNG")
img_str = base64.b64encode(buffered.getvalue()).decode("utf-8")
return {
"headers": {"Content-Type": "image/png"},
"statusCode": 200,
"body": img_str,
"isBase64Encoded": True,
}
```Now redeploy and hit the endpoint! It’s going to take a while 😅 but hey we aren’t optimizing for speed but simplicity and cost here.
```
response = signed_request(
credentials,
"POST",
"https://ybajg5r7frv6zmbjeot3yiaiee0askzy.lambda-url.us-west-2.on.aws/",
service_name="lambda",
region="us-west-2",
data={"prompt": "a turtle walks into a bar and says, 'ow!'"},
)
print(response.content)
img = Image.open(BytesIO(response.content))
img.show()
```Notice how we make a POST request now because we are sending over some JSON data with the prompt. This should yield an image. It’s not a great image but it is an image from a diffusion model. From this point, you’ll probably want to play with some of the parameters to get the defaults working well. But we did successfully generate an image from a diffusion model on a Lambda. Pretty neat!

Conclusion
We covered a lot of ground today from creating a CDK Lambda function to modifying it with a baked in model. The techniques we used here are broadly applicable in model deployment and building microservices in general. Happy Building! The full code for this example can be found on my GitHub here: